HashеҮҪж•°еңЁеӨҡдёӘйўҶеҹҹеқҮжңүеә”з”ЁпјҢиҖҢеңЁж•°еӯ—зӯҫеҗҚе’Ңж•°жҚ®еә“е®һзҺ°ж—¶еҸҲз”Ёзҡ„жңҖеӨҡпјҢжҜ”еҰӮеҹәдәҺhashзҡ„зҙўеј•пјҢжҳҜжңҖеҘҪзҡ„еҚ•еҖјжҹҘжүҫзҙўеј•пјӣ
еҗҢж—¶пјҢеңЁеҪ“еүҚж•°жҚ®зҲҶзӮёзҡ„еңәжҷҜдёӢпјҢжү§иЎҢзӣёдјјitemзҡ„жҹҘжүҫж—¶пјҢеңЁеҶ…еӯҳеҸ—йҷҗж—¶пјҢеқҮеҸҜд»ҘйҮҮеҸ–LSHпјҲlocal sensitive hashпјүиҝӣиЎҢеҲҶж®өеӨ„зҗҶгҖӮ
е…·дҪ“з”ЁйҖ”еҫҲеӨҡпјҢдёҚиөҳиҝ°пјҢдёӢйқўд»Ӣз»ҚдёҖдәӣеёёз”Ёзҡ„зҹҘиҜҶпјҡ
1гҖҒhashеҮҪж•°жң¬иҙЁпјӣ
2гҖҒз®ҖеҚ•зҡ„hashеҮҪж•°з”ҹжҲҗжі•пјӣ
3гҖҒhashзҡ„еҶІзӘҒж¶Ҳи§Јпјӣ
еҸҰеӨ–пјҡеҲҶдә«дёҖдёӘеӣҪеӨ–зүӣдәәзҡ„дёӘдәәзҪ‘з«ҷпјҢжңүйқһеёёе…Ёйқўзҡ„hashз®—жі•еҲ—иЎЁпјҡhttp://burtleburtle.net/bob/hash/
дё»иҰҒеҶ…е®№пјҡ
1гҖҒhashзҡ„жң¬иҙЁ
HashеҮҪж•°жҳҜжҢҮжҠҠдёҖдёӘеӨ§иҢғеӣҙжҳ е°„еҲ°дёҖдёӘе°ҸиҢғеӣҙгҖӮжҠҠеӨ§иҢғеӣҙжҳ е°„еҲ°дёҖдёӘе°ҸиҢғеӣҙзҡ„зӣ®зҡ„еҫҖеҫҖжҳҜдёәдәҶиҠӮзңҒз©әй—ҙгҖӮеңЁиҖғиҷ‘дҪҝз”ЁHashеҮҪж•°д№ӢеүҚпјҢйңҖиҰҒжҳҺзҷҪе®ғзҡ„еҮ дёӘйҷҗеҲ¶пјҡ
пјҲ1пјү. Hashзҡ„дё»иҰҒеҺҹзҗҶе°ұжҳҜжҠҠеӨ§иҢғеӣҙжҳ е°„еҲ°е°ҸиҢғеӣҙпјӣжүҖд»ҘпјҢдҪ иҫ“е…Ҙзҡ„е®һйҷ…еҖјзҡ„дёӘж•°еҝ…йЎ»е’Ңе°ҸиҢғеӣҙзӣёеҪ“жҲ–иҖ…жҜ”е®ғжӣҙе°ҸгҖӮдёҚ然еҶІзӘҒе°ұдјҡеҫҲеӨҡгҖӮ
гҖҖгҖҖпјҲ2пјү. з”ұдәҺHashйҖјиҝ‘еҚ•еҗ‘еҮҪж•°пјӣжүҖд»ҘпјҢдҪ еҸҜд»Ҙз”Ёе®ғжқҘеҜ№ж•°жҚ®иҝӣиЎҢеҠ еҜҶгҖӮ
гҖҖгҖҖпјҲ3пјү. дёҚеҗҢзҡ„еә”з”ЁеҜ№HashеҮҪж•°жңүзқҖдёҚеҗҢзҡ„иҰҒжұӮпјӣжҜ”еҰӮпјҢз”ЁдәҺеҠ еҜҶзҡ„HashеҮҪж•°дё»иҰҒиҖғиҷ‘е®ғе’ҢеҚ•йЎ№еҮҪж•°зҡ„е·®и·қпјҢиҖҢз”ЁдәҺжҹҘжүҫзҡ„HashеҮҪж•°дё»иҰҒиҖғиҷ‘е®ғжҳ е°„еҲ°е°ҸиҢғеӣҙзҡ„еҶІзӘҒзҺҮгҖӮ
HashеҮҪж•°еҘҪеқҸйқһиҜ„еҲӨж ҮеҮҶпјҡз®ҖеҚ•е’ҢеқҮеҢҖгҖӮ
гҖҖз®ҖеҚ•жҢҮж•ЈеҲ—еҮҪж•°зҡ„и®Ўз®—з®ҖеҚ•еҝ«йҖҹпјӣ
гҖҖеқҮеҢҖжҢҮеҜ№дәҺе…ій”®еӯ—йӣҶеҗҲдёӯзҡ„д»»дёҖе…ій”®еӯ—пјҢж•ЈеҲ—еҮҪж•°иғҪд»ҘзӯүжҰӮзҺҮе°Ҷе…¶жҳ е°„еҲ°иЎЁз©әй—ҙзҡ„д»»дҪ•дёҖдёӘдҪҚзҪ®дёҠгҖӮд№ҹе°ұжҳҜиҜҙпјҢж•ЈеҲ—еҮҪж•°иғҪе°ҶеӯҗйӣҶKйҡҸжңәеқҮеҢҖең°еҲҶеёғеңЁиЎЁзҡ„ең°еқҖйӣҶ{0пјҢ1пјҢвҖҰпјҢm-1}дёҠпјҢд»ҘдҪҝеҶІзӘҒжңҖе°ҸеҢ–гҖӮ
2гҖҒеёёз”Ёhashз”ҹжҲҗж–№жі•
п»ҝп»ҝп»ҝп»ҝп»ҝп»ҝп»ҝп»ҝ
еёёз”Ёзҡ„ж•ЈеҲ—еҮҪж•°жһ„йҖ жңү6з§Қж–№жі•пјҢ1пјҢзӣҙжҺҘе®ҡеқҖжі•пјӣ 2пјҢж•°еӯ—еҲҶжһҗжі•пјӣ 3 пјҢе№іж–№еҸ–дёӯжі•пјӣ4пјҢжҠҳеҸ жі•пјӣ5пјҢйҷӨз•ҷдҪҷж•°жі•пјӣ6пјҢдјӘйҡҸжңәж•°жі•
пјҲ1пјүе№іж–№еҸ–дёӯжі•
гҖҖе…·дҪ“ж–№жі•пјҡе…ҲйҖҡиҝҮжұӮе…ій”®еӯ—зҡ„е№іж–№еҖјжү©еӨ§зӣёиҝ‘ж•°зҡ„е·®еҲ«пјҢ然еҗҺж №жҚ®иЎЁй•ҝеәҰеҸ–дёӯй—ҙзҡ„еҮ дҪҚж•°дҪңдёәж•ЈеҲ—еҮҪж•°еҖјгҖӮеҸҲеӣ дёәдёҖдёӘд№ҳз§Ҝзҡ„дёӯй—ҙеҮ дҪҚж•°е’Ңд№ҳж•°зҡ„жҜҸдёҖдҪҚйғҪзӣёе…іпјҢжүҖд»Ҙз”ұжӯӨдә§з”ҹзҡ„ж•ЈеҲ—ең°еқҖиҫғдёәеқҮеҢҖгҖӮ
гҖҖгҖҗдҫӢгҖ‘е°ҶдёҖз»„е…ій”®еӯ—(0100пјҢ0110пјҢ1010пјҢ1001пјҢ0111)е№іж–№еҗҺеҫ—
(0010000пјҢ0012100пјҢ1020100пјҢ1002001пјҢ0012321)
гҖҖиӢҘеҸ–иЎЁй•ҝдёә1000пјҢеҲҷеҸҜеҸ–дёӯй—ҙзҡ„дёүдҪҚж•°дҪңдёәж•ЈеҲ—ең°еқҖйӣҶпјҡ
(100пјҢ121пјҢ201пјҢ020пјҢ123)гҖӮ
зӣёеә”зҡ„ж•ЈеҲ—еҮҪж•°з”ЁCе®һзҺ°еҫҲз®ҖеҚ•пјҡ
int Hash(int key){ //еҒҮи®ҫkeyжҳҜ4дҪҚж•ҙж•°
key*=keyпјӣ key/=100пјӣ //е…ҲжұӮе№іж–№еҖјпјҢеҗҺеҺ»жҺүжң«е°ҫзҡ„дёӨдҪҚж•°
return keyпј…1000пјӣ //еҸ–дёӯй—ҙдёүдҪҚж•°дҪңдёәж•ЈеҲ—ең°еқҖиҝ”еӣһ
}
пјҲ2пјүйҷӨдҪҷжі•
гҖҖиҜҘж–№жі•жҳҜжңҖдёәз®ҖеҚ•еёёз”Ёзҡ„дёҖз§Қж–№жі•гҖӮе®ғжҳҜд»ҘиЎЁй•ҝmжқҘйҷӨе…ій”®еӯ—пјҢеҸ–е…¶дҪҷж•°дҪңдёәж•ЈеҲ—ең°еқҖпјҢеҚі h(key)=keyпј…m
гҖҖиҜҘж–№жі•зҡ„е…ій”®жҳҜйҖүеҸ–mгҖӮйҖүеҸ–зҡ„mеә”дҪҝеҫ—ж•ЈеҲ—еҮҪж•°еҖје°ҪеҸҜиғҪдёҺе…ій”®еӯ—зҡ„еҗ„дҪҚзӣёе…ігҖӮmжңҖеҘҪдёәзҙ ж•°гҖӮ
гҖҖгҖҗдҫӢгҖ‘иӢҘйҖүmжҳҜе…ій”®еӯ—зҡ„еҹәж•°зҡ„е№Ӯж¬ЎпјҢеҲҷе°ұзӯүдәҺжҳҜйҖүжӢ©е…ій”®еӯ—зҡ„жңҖеҗҺиӢҘе№ІдҪҚж•°еӯ—дҪңдёәең°еқҖпјҢиҖҢдёҺй«ҳдҪҚж— е…ігҖӮдәҺжҳҜй«ҳдҪҚдёҚеҗҢиҖҢдҪҺдҪҚзӣёеҗҢзҡ„е…ій”®еӯ—еқҮдә’дёәеҗҢд№үиҜҚгҖӮ
гҖҖгҖҗдҫӢгҖ‘иӢҘе…ій”®еӯ—жҳҜеҚҒиҝӣеҲ¶ж•ҙж•°пјҢе…¶еҹәдёә10пјҢеҲҷеҪ“m=100ж—¶пјҢ159пјҢ259пјҢ359пјҢвҖҰпјҢзӯүеқҮдә’дёәеҗҢд№үиҜҚгҖӮ
пјҲ3пјүзӣёд№ҳеҸ–ж•ҙжі•
гҖҖиҜҘж–№жі•еҢ…жӢ¬дёӨдёӘжӯҘйӘӨпјҡйҰ–е…Ҳз”Ёе…ій”®еӯ—keyд№ҳдёҠжҹҗдёӘеёёж•°A(0<A<1)пјҢ并жҠҪеҸ–еҮәkey.Aзҡ„е°Ҹж•°йғЁеҲҶпјӣ然еҗҺз”Ёmд№ҳд»ҘиҜҘе°Ҹж•°еҗҺеҸ–ж•ҙгҖӮеҚіпјҡ
гҖҖиҜҘж–№жі•жңҖеӨ§зҡ„дјҳзӮ№жҳҜйҖүеҸ–mдёҚеҶҚеғҸйҷӨдҪҷжі•йӮЈж ·е…ій”®гҖӮжҜ”еҰӮпјҢе®Ңе…ЁеҸҜйҖүжӢ©е®ғжҳҜ2зҡ„ж•ҙж•°ж¬Ўе№ӮгҖӮиҷҪ然иҜҘж–№жі•еҜ№д»»дҪ•Aзҡ„еҖјйғҪйҖӮз”ЁпјҢдҪҶеҜ№жҹҗдәӣеҖјж•ҲжһңдјҡжӣҙеҘҪгҖӮKnuthе»әи®®йҖүеҸ–
гҖҖиҜҘеҮҪж•°зҡ„Cд»Јз Ғдёәпјҡ
int Hash(int key){
double d=key *Aпјӣ //дёҚеҰЁи®ҫAе’Ңmе·Іжңүе®ҡд№ү
return (int)(m*(d-(int)d))пјӣ//(int)иЎЁзӨәејәеҲ¶иҪ¬жҚўеҗҺйқўзҡ„иЎЁиҫҫејҸдёәж•ҙж•°
}
пјҲ4пјүйҡҸжңәж•°жі•
гҖҖйҖүжӢ©дёҖдёӘйҡҸжңәеҮҪж•°пјҢеҸ–е…ій”®еӯ—зҡ„йҡҸжңәеҮҪж•°еҖјдёәе®ғзҡ„ж•ЈеҲ—ең°еқҖпјҢеҚі
h(key)=random(key)
гҖҖе…¶дёӯrandomдёәдјӘйҡҸжңәеҮҪж•°пјҢдҪҶиҰҒдҝқиҜҒеҮҪж•°еҖјжҳҜеңЁ0еҲ°m-1д№Ӣй—ҙгҖӮ
3гҖҒhashзҡ„еҶІзӘҒж¶Ҳи§Ј
1)еҶІзӘҒжҳҜеҰӮдҪ•дә§з”ҹзҡ„пјҹ
дёҠж–Үдёӯи°ҲеҲ°пјҢе“ҲеёҢеҮҪж•°жҳҜжҢҮеҰӮдҪ•еҜ№е…ій”®еӯ—иҝӣиЎҢзј–еқҖзҡ„规еҲҷпјҢиҝҷйҮҢзҡ„е…ій”®еӯ—зҡ„иҢғеӣҙеҫҲе№ҝпјҢеҸҜи§Ҷдёәж— йҷҗйӣҶпјҢеҰӮдҪ•дҝқиҜҒж— йҷҗйӣҶзҡ„еҺҹж•°жҚ®еңЁзј–еқҖзҡ„ж—¶еҖҷдёҚдјҡеҮәзҺ°йҮҚеӨҚе‘ўпјҹ规еҲҷжң¬иә«ж— жі•е®һзҺ°иҝҷдёӘзӣ®зҡ„гҖӮдёҫдёҖдёӘдҫӢеӯҗпјҢд»Қ然用зҸӯзә§еҗҢеӯҰеҒҡжҜ”е–»пјҢзҺ°жңүеҰӮдёӢеҗҢеӯҰж•°жҚ®
еј дёүпјҢжқҺеӣӣпјҢзҺӢдә”пјҢиөөеҲҡпјҢеҗҙйңІ.....
еҒҮеҰӮжҲ‘们编еқҖ规еҲҷдёәеҸ–姓ж°Ҹдёӯ姓зҡ„ејҖеӨҙеӯ—жҜҚеңЁеӯ—жҜҚиЎЁзҡ„зӣёеҜ№дҪҚзҪ®дҪңдёәең°еқҖпјҢеҲҷдјҡдә§з”ҹеҰӮдёӢзҡ„е“ҲеёҢиЎЁ
| дҪҚзҪ® |
еӯ—жҜҚ |
姓еҗҚ |
|
| 0 |
a |
|
|
| 1 |
b |
|
|
| 2 |
c |
|
|
...
...
..
жҲ‘们注ж„ҸеҲ°пјҢзҒ°иүІиғҢжҷҜж ҮзӨәзҡ„дёӨиЎҢйҮҢйқўпјҢе…ій”®еӯ—зҺӢдә”пјҢеҗҙйңІиў«зј–еҲ°дәҶеҗҢдёҖдёӘдҪҚзҪ®пјҢе…ій”®еӯ—еј дёүпјҢиөөеҲҡд№ҹиў«зј–еҲ°дәҶеҗҢдёҖдёӘдҪҚзҪ®гҖӮиҖҒеёҲеҶҚжӢҝеҸ·жқҘжүҫеј дёүпјҢеә§дҪҚдёҠжңүдёӨдёӘдәәпјҢ"дҪ 们дҝ©и°ҒжҳҜеј дёүпјҹ"
2)еҰӮдҪ•и§ЈеҶіеҶІзӘҒй—®йўҳ
既然дёҚиғҪйҒҝе…ҚеҶІзӘҒпјҢйӮЈд№ҲеҰӮдҪ•и§ЈеҶіеҶІзӘҒе‘ўпјҢжҳҫ然йңҖиҰҒйҷ„еҠ зҡ„жӯҘйӘӨгҖӮйҖҡиҝҮиҝҷдәӣжӯҘйӘӨпјҢд»ҘеҲ¶е®ҡжӣҙеӨҡзҡ„规еҲҷжқҘз®ЎзҗҶе…ій”®еӯ—йӣҶеҗҲпјҢйҖҡеёёзҡ„еҠһжі•жңү:
a)ејҖж”ҫең°еқҖжі•
ејҖж”ҫең°жү§жі•жңүдёҖдёӘе…¬ејҸ:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
е…¶дёӯпјҢmдёәе“ҲеёҢиЎЁзҡ„иЎЁй•ҝгҖӮdi жҳҜдә§з”ҹеҶІзӘҒзҡ„ж—¶еҖҷзҡ„еўһйҮҸеәҸеҲ—гҖӮеҰӮжһңdiеҖјеҸҜиғҪдёә1,2,3,...m-1пјҢз§°зәҝжҖ§жҺўжөӢеҶҚж•ЈеҲ—гҖӮ
еҰӮжһңdiеҸ–1пјҢеҲҷжҜҸж¬ЎеҶІзӘҒд№ӢеҗҺпјҢеҗ‘еҗҺ移еҠЁ1дёӘдҪҚзҪ®.еҰӮжһңdiеҸ–еҖјеҸҜиғҪдёә1,-1,2,-2,4,-4,9,-9,16,-16,...k*k,-k*k(k<=m/2)
з§°дәҢж¬ЎжҺўжөӢеҶҚж•ЈеҲ—гҖӮеҰӮжһңdiеҸ–еҖјеҸҜиғҪдёәдјӘйҡҸжңәж•°еҲ—гҖӮз§°дјӘйҡҸжңәжҺўжөӢеҶҚж•ЈеҲ—гҖӮд»Қ然д»ҘеӯҰз”ҹжҺ’еҸ·дҪңдёәдҫӢеӯҗпјҢ
зҺ°жңүдёӨеҗҚеҗҢеӯҰпјҢжқҺеӣӣпјҢеҗҙз”ЁгҖӮжқҺеӣӣдёҺеҗҙз”ЁдәӢе…Ҳе·ІжҺ’еҘҪеәҸпјҢзҺ°ж–°жқҘдёҖеҗҚеҗҢеӯҰпјҢеҗҚеӯ—еҸ«зҺӢдә”пјҢеҜ№е®ғиҝӣиЎҢзј–еҲ¶
| 10.. |
.... |
22 |
.. |
.. |
25 |
| жқҺеӣӣ.. |
.... |
еҗҙз”Ё |
.. |
.. |
25 |
иөөеҲҡжңӘжқҘд№ӢеүҚ
| 10.. |
.. |
22 |
23 |
25 |
| жқҺеӣӣ.. |
|
еҗҙз”Ё |
зҺӢдә” |
|
(a)зәҝжҖ§жҺўжөӢеҶҚж•ЈеҲ—еҜ№иөөеҲҡиҝӣиЎҢзј–еқҖпјҢдё”di=1
| 10... |
20 |
22 |
.. |
25 |
| жқҺеӣӣ.. |
зҺӢдә” |
еҗҙз”Ё |
|
|
(b)дәҢж¬ЎжҺўжөӢеҶҚж•ЈеҲ—пјҢдё”di=-2
| 1... |
10... |
22 |
.. |
25 |
| зҺӢдә”.. |
жқҺеӣӣ.. |
еҗҙз”Ё |
|
|
(c)дјӘйҡҸжңәжҺўжөӢеҶҚж•ЈеҲ—,дјӘйҡҸжңәеәҸеҲ—дёә:5,3,2
b)еҶҚе“ҲеёҢжі•
еҪ“еҸ‘з”ҹеҶІзӘҒж—¶пјҢдҪҝ用第дәҢдёӘгҖҒ第дёүдёӘгҖҒе“ҲеёҢеҮҪж•°и®Ўз®—ең°еқҖпјҢзӣҙеҲ°ж— еҶІзӘҒж—¶гҖӮзјәзӮ№пјҡи®Ўз®—ж—¶й—ҙеўһеҠ гҖӮ
жҜ”еҰӮдёҠйқўз¬¬дёҖж¬ЎжҢү照姓йҰ–еӯ—жҜҚиҝӣиЎҢе“ҲеёҢпјҢеҰӮжһңдә§з”ҹеҶІзӘҒеҸҜд»ҘжҢү照姓еӯ—жҜҚйҰ–еӯ—жҜҚ第дәҢдҪҚиҝӣиЎҢе“ҲеёҢпјҢеҶҚеҶІзӘҒпјҢ第дёүдҪҚпјҢзӣҙеҲ°дёҚеҶІзӘҒдёәжӯў
c)й“ҫең°еқҖжі•
е°ҶжүҖжңүе…ій”®еӯ—дёәеҗҢд№үиҜҚзҡ„и®°еҪ•еӯҳеӮЁеңЁеҗҢдёҖзәҝжҖ§й“ҫиЎЁдёӯгҖӮеҰӮдёӢпјҡ
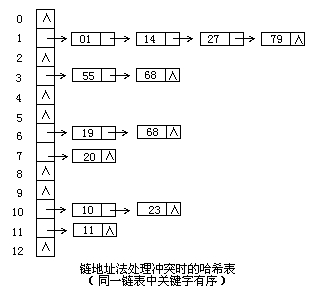
еӣ жӯӨиҝҷз§Қж–№жі•пјҢеҸҜд»Ҙиҝ‘дјјзҡ„и®ӨдёәжҳҜзӯ’еӯҗйҮҢйқўеҘ—зӯ’еӯҗ
d.е»әз«ӢдёҖдёӘе…¬е…ұжәўеҮәеҢәпјҲжҜ”иҫғеёёи§ҒдәҺе®һйҷ…ж“ҚдҪңдёӯпјү
еҒҮи®ҫе“ҲеёҢеҮҪж•°зҡ„еҖјеҹҹдёә[0,m-1],еҲҷи®ҫеҗ‘йҮҸHashTable[0..m-1]дёәеҹәжң¬иЎЁпјҢеҸҰеӨ–и®ҫз«ӢеӯҳеӮЁз©әй—ҙеҗ‘йҮҸOverTable[0..v]з”Ёд»ҘеӯҳеӮЁеҸ‘з”ҹеҶІзӘҒзҡ„и®°еҪ•гҖӮ
з»ҸиҝҮд»ҘдёҠж–№жі•пјҢеҹәжң¬еҸҜд»Ҙи§ЈеҶіжҺүhashз®—жі•еҶІзӘҒзҡ„й—®йўҳгҖӮ
жіЁ:д№ӢжүҖд»Ҙдјҡз®ҖеҚ•еҫ—д»Ӣз»ҚдәҶhashпјҢжҳҜдёәдәҶжӣҙеҘҪзҡ„еӯҰд№ lzwз®—жі•пјҢеӯҰд№ lzwз®—жі•жҳҜдёәдәҶжӣҙеҘҪзҡ„з ”з©¶gifж–Ү件结жһ„пјҢжңҖеҗҺпјҢжҲ‘е°ҶиҜҰз»Ҷзҡ„йҳҗиҝ°дёҖдёӢgifж–Ү件жҳҜеҰӮдҪ•жһ„жҲҗзҡ„пјҢеҰӮдҪ•й«ҳж•Ҳж“ҚдҪңжӯӨз§Қзұ»еһӢж–Ү件гҖӮ
йҷӨдәҶдёҠиҜүзҡ„еҮ з§Қж–№жі•пјҢиҝҳжңүи®ёеӨҡз”ЁдәҺж•ЈеҲ—иЎЁзҡ„ж–№жі•пјҢжҜ”еҰӮж•ЈеҲ—еҮҪж•°дёҚеҘҪжҲ–иЈ…еЎ«еӣ еӯҗиҝҮеӨ§пјҢйғҪдјҡдҪҝе Ҷз§ҜзҺ°иұЎеҠ еү§гҖӮдёәдәҶеҮҸе°‘е Ҷз§Ҝзҡ„еҸ‘з”ҹпјҢдёҚиғҪеғҸзәҝжҖ§жҺўжҹҘжі•йӮЈж ·жҺўжҹҘдёҖдёӘйЎәеәҸзҡ„ең°еқҖеәҸеҲ—(зӣёеҪ“дәҺйЎәеәҸжҹҘжүҫ)пјҢиҖҢеә”дҪҝжҺўжҹҘеәҸеҲ—и·іи·ғејҸең°ж•ЈеҲ—еңЁж•ҙдёӘж•ЈеҲ—иЎЁдёӯгҖӮиЎҚз”ҹеҮәдәҢж¬ЎжҺўжҹҘжі•пјҢеҸҢйҮҚж•ЈеҲ—иЎЁжі•гҖӮ
жң¬ж–ҮиҪ¬иҮӘпјҡ http://blog.csdn.net/yumengkk/article/details/7031357
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
иҮӘе·ұж•ҙзҗҶзҡ„ж•°жҚ®з»“жһ„е“ҲеёҢиЎЁиҜҰи§ЈпјҢеҸӮиҖғе…¶д»–еҚҡе®ўгҖҒз®—жі•еҜји®әгҖӮеҢ…жӢ¬е“ҲеёҢиЎЁжһ„йҖ ж–№жі•гҖҒи§ЈеҶіеҶІзӘҒзҡ„ж–№жі•гҖҒеҢ…еҗ«зүӣе®ўдёҠзҡ„з»ғд№ йўҳгҖӮ
е“ҲеёҢиЎЁ
NULL еҚҡж–Үй“ҫжҺҘпјҡhttps://839127406.iteye.com/blog/1966131
е“ҲеёҢиЎЁи®Іи§Ј е“ҲеёҢиЎЁи®Іи§Ј е“ҲеёҢеҮҪж•°; е“ҲеёҢиЎЁ
1гҖҒHashдё»иҰҒз”ЁдәҺдҝЎжҒҜе®үе…ЁйўҶеҹҹдёӯеҠ еҜҶз®—жі•пјҢе®ғжҠҠдёҖдәӣдёҚеҗҢй•ҝеәҰзҡ„дҝЎжҒҜиҪ¬еҢ–жҲҗжқӮд№ұзҡ„12 2гҖҒжҹҘжүҫпјҡе“ҲеёҢиЎЁпјҢеҸҲз§°дёәж•ЈеҲ—пјҢжҳҜдёҖз§ҚжӣҙеҠ еҝ«жҚ·зҡ„жҹҘжүҫжҠҖжңҜ 3гҖҒHashиЎЁеңЁжө·йҮҸ
е“ҲеёҢиЎЁ
жң¬ж–Үе®һдҫӢи®Іиҝ°дәҶJSжЁЎжӢҹе®һзҺ°е“ҲеёҢиЎЁеҸҠеә”з”ЁгҖӮеҲҶдә«з»ҷеӨ§е®¶дҫӣеӨ§е®¶еҸӮиҖғпјҢе…·дҪ“еҰӮдёӢпјҡ еңЁз®—жі•дёӯпјҢе°Өе…¶жҳҜжңүе…іж•°з»„зҡ„з®—жі•дёӯпјҢе“ҲеёҢиЎЁзҡ„дҪҝз”ЁеҸҜд»ҘеҫҲеҘҪзҡ„и§ЈеҶій—®йўҳпјҢжүҖд»ҘиҝҷзҜҮж–Үз« дјҡи®°еҪ•дёҖдәӣжңүе…іjsе®һзҺ°е“ҲеёҢ表并з»ҷеҮәи§ЈеҶіе®һйҷ…й—®йўҳзҡ„дҫӢеӯҗ...
SQL Server 2014жҺЁеҮәзҡ„зҡ„ж–°зҙўеј•зұ»еһӢеҸ«еҒҡ hash indexгҖӮд»Ӣз»Қhash indexд№ӢеүҚдёҖе®ҡиҰҒд»Ӣз»Қе“ҲеёҢеҮҪж•°иҝҷж ·дјҡи®©еӨ§е®¶жӣҙжҳҺзҷҪе“ҲеёҢзҙўеј•зҡ„еҺҹзҗҶпјҢжңүйңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
дё»иҰҒд»Ӣз»ҚдәҶиҜҰи§Јpythonе®һзҺ°еҸҜи§ҶеҢ–зҡ„MD5гҖҒsha256е“ҲеёҢеҠ еҜҶе°Ҹе·Ҙе…·пјҢж–ҮдёӯйҖҡиҝҮзӨәдҫӢд»Јз Ғд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢеҜ№еӨ§е®¶зҡ„еӯҰд№ жҲ–иҖ…е·ҘдҪңе…·жңүдёҖе®ҡзҡ„еҸӮиҖғеӯҰд№ д»·еҖјпјҢйңҖиҰҒзҡ„жңӢеҸӢ们дёӢйқўйҡҸзқҖе°Ҹзј–жқҘдёҖиө·еӯҰд№ еӯҰд№ еҗ§
дё»иҰҒд»Ӣз»ҚдәҶC#дёӯе“ҲеёҢиЎЁ(HashTable)з”Ёжі•,з®ҖеҚ•и®Іиҝ°дәҶе“ҲеёҢиЎЁзҡ„еҺҹзҗҶ并结еҗҲе®һдҫӢеҪўејҸиҜҰз»ҶеҲҶжһҗдәҶC#й’ҲеҜ№е“ҲеёҢиЎЁиҝӣиЎҢж·»еҠ гҖҒ移йҷӨгҖҒеҲӨж–ӯгҖҒйҒҚеҺҶгҖҒжҺ’еәҸзӯүж“ҚдҪңзҡ„е®һзҺ°жҠҖе·§,йңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
Javaдёӯе“ҲеёҢиЎЁ(Hashtable)жҳҜеҰӮдҪ•е®һзҺ°зҡ„е‘ўпјҹHashtableдёӯжңүдёҖдёӘеҶ…йғЁзұ»EntryпјҢз”ЁжқҘдҝқеӯҳеҚ•е…ғж•°жҚ®пјҢжҲ‘们用жқҘжһ„е»әе“ҲеёҢиЎЁзҡ„жҜҸдёҖдёӘж•°жҚ®жҳҜEntryзҡ„дёҖдёӘе®һдҫӢгҖӮеҒҮи®ҫжҲ‘们дҝқеӯҳдёӢйқўдёҖз»„ж•°жҚ®пјҢ第дёҖеҲ—дҪңдёәkey, 第дәҢеҲ—дҪңдёәvalueгҖӮ
//$2y$10$uOegXJ09qznQsKvPfxr61uWjpJBxVDH2KGJQVnodzjnglhs2WTwHuдҪ е°ҶжіЁж„ҸеҲ°жҲ‘们并没жңүз»ҷиҝҷдёӘе“ҲеёҢеҠ д»»дҪ•йҖүйЎ№гҖӮзҺ°еңЁеҸҜз”Ёзҡ„йҖүйЎ№иў«йҷҗе®ҡдёәдёӨдёӘпјҡ cost е’ҢsaltгҖӮеҰ–ж·»еҠ йҖүйЎ№дҪ йңҖиҰҒеҲӣе»әдёҖдёӘе…іиҒ”ж•°з»„гҖӮеӨҚеҲ¶д»Јз Ғ д»Јз ҒеҰӮдёӢ:$
дё»иҰҒд»Ӣз»ҚдәҶеҜҶз Ғе“ҲеёҢеҮҪж•° Bcryptзҡ„жңҖеӨ§еҜҶз Ғй•ҝеәҰйҷҗеҲ¶иҜҰи§Јзҡ„зӣёе…іиө„ж–ҷ,йңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
жӯӨж–ҮжЎЈпјҢеҢ…еҗ«дәҶ ж ‘пјҢдәҢеҸүж ‘пјҢж•°жҚ®з»“жһ„дёҺз®—жі•пјҢжҺ’еәҸпјҢе“ҲеёҢиЎЁзӯүйҡҫзӮ№йҮҚзӮ№иҜҰи§ЈгҖӮеёҢжңӣеҜ№дәҺеӯҰд№ жңүеё®еҠ©гҖӮ
дё»иҰҒд»Ӣз»ҚдәҶCиҜӯиЁҖе®һзҺ°ж•ЈеҲ—иЎЁпјҲе“ҲеёҢHashиЎЁ)е®һдҫӢиҜҰи§Јзҡ„зӣёе…іиө„ж–ҷ,йңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
йҖҡиҝҮдёҖж—Ҹе“ҲеёҢеҮҪж•°е°Ҷз©әй—ҙжүҖжңүзӮ№жҳ е°„еҲ°nдёӘе“ҲеёҢиЎЁдёӯпјҢn=||пјҢеҚіжҜҸдёӘе“ҲеёҢеҮҪж•°fеҜ№еә”дёҖдёӘе“ҲеёҢиЎЁпјҢжҜҸдёӘе“ҲеёҢиЎЁйғҪеӯҳж”ҫзқҖз©әй—ҙжүҖжңүзҡ„зӮ№гҖӮеҜ№дәҺз»ҷе®ҡзҡ„жҹҘиҜўеӯҗqпјҢеҲҶеҲ«и®Ўз®—гҖҒгҖҒвҖҰгҖҒпјҢпјҢi=1,2,вҖҰ,n гҖӮд»ҘжүҖжңүиҗҪе…Ҙзҡ„е“ҲеёҢиЎЁдёӯзҡ„жЎ¶дёӯжүҖжңүзӮ№...
HashMapеҶ…йғЁдҪҝз”Ёе“ҲеёҢиЎЁжқҘе®һзҺ°пјҢйҖҡиҝҮе°Ҷй”®жҳ е°„еҲ°е“ҲеёҢиЎЁдёӯзҡ„дёҖдёӘдҪҚзҪ®жқҘеҝ«йҖҹжҹҘжүҫе’ҢжҸ’е…Ҙе…ғзҙ гҖӮ HashMapзҡ„дё»иҰҒзү№зӮ№жҳҜпјҡ йқһзәҝзЁӢе®үе…ЁпјҡеҰӮжһңеӨҡдёӘзәҝзЁӢеҗҢж—¶и®ҝй—®еҗҢдёҖдёӘHashMapе®һдҫӢпјҢеҸҜиғҪдјҡеҜјиҮҙж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳгҖӮеӣ жӯӨпјҢеңЁдҪҝз”Ё...
дё»иҰҒд»Ӣз»ҚдәҶC++ е®һзҺ°е“ҲеёҢиЎЁзҡ„е®һдҫӢзҡ„зӣёе…іиө„ж–ҷ,иҝҷйҮҢдҪҝз”ЁC++е®һзҺ°е“ҲеёҢиЎЁзҡ„е®һдҫӢеё®еҠ©еӨ§е®¶еҪ»еә•зҗҶи§Је“ҲеёҢиЎЁзҡ„еҺҹзҗҶпјҢйңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ